Building Base Case Operating Models
Building-Base-Case-Operating-Models.Rmd1 Introduction
This article describes the process to import output from the Beaufort Assessment Model (BAM) and create the Base Case multi-species and multi-fleet operating models (OMs) used by the openMSE framework.
1.1 Prerequistes
The latest development versions of MSEtool and bamExtras need to be installed from GitHub:
# install.packages('pak')
pak::pkg_install('nikolaifish/bamExtras')
pak::pkg_install('blue-matter/MSEtool')2 OM Specifications
The number of simulations (nsim) and number of projection years (proyears) need to be specified for an OM. Here we are setting them as global variables so that each OM we create has the same number of stochastic simulations and projection years:
nsim <- 100 # number of simulations
proyears <- 25 # number of projection yearsAn OM also requires the specification of an Observation Model. The Observation Model is used to simulate fishery data to be used be management procedures in the projection phase of the closed-loop simulation testing.
We are using Perfect_Info as the fishery data are not currently used within the management options (only static management options are currently being explored). This can be changed later if dynamic management options that respond to the observed fishery data are added to the analysis.
Obs_Model <- MSEtool::Perfect_Info3 Case Study Stocks
The current analysis is focused on three stocks: red snapper Lutjanus campechanus, gag grouper Mycteroperca microlepis, and black seabass Centropristis striata. The MSE framework is flexible, and more stocks can be added to the analysis following the same process used here.
Here we demonstrate creating OMs for the three case study stocks.
The most recent BAM assessments are used:
4 Import SEDAR Assessments
The BAM assessments are imported from the bamExtras package:
rdat_RS <- bamExtras::rdat_RedSnapper |> bamExtras::standardize_rdat()
rdat_GG <- bamExtras::rdat_GagGrouper |> bamExtras::standardize_rdat()
rdat_BS <- bamExtras::rdat_BlackSeaBass |> bamExtras::standardize_rdat()5 Create Single-Stock Operating Models
The BAM2MOM function is used to create the openMSE operating model objects:
OM_RS <- BAM2MOM(rdat_RS, stock_name='Red Snapper',
Obs=Obs_Model,
nsim=nsim, proyears=proyears)
OM_GG <- BAM2MOM(rdat_GG, stock_name='Gag Grouper',
Obs=Obs_Model,
nsim=nsim, proyears=proyears)
OM_BS <- BAM2MOM(rdat_BS, stock_name='Black Sea Bass',
Obs=Obs_Model,
nsim=nsim, proyears=proyears)These OMs could now be used within the openMSE framework. However, if we wish to combine the OMs into a single multi-stock OM (or model them individually under the assumption they are being managed together), we need to create a common fleet structure for all OMs.
5.1 Define Fleet Structure
Here we create a data frame with the names of the fleets within each OM:
fleet_names_df <- dplyr::bind_rows(
data.frame(Stock='Red Snapper', Fleets=names(OM_RS@Fleets[[1]])),
data.frame(Stock='Gag Grouper', Fleets=names(OM_GG@Fleets[[1]])),
data.frame(Stock='Black Sea Bass', Fleets=names(OM_BS@Fleets[[1]]))
)In order to combine these single stock OMs together, each OM must have the same fleet structure for all stocks in the OM, even if those fleets are not actively fishing on a particular stock.
The stocks have some fleets in common (e.g., Commercial hook and line (cHL)) and some unique fleets (e.g., Gag Grouper Commercial dive (cDV)). The landings and discards are also modeled as separate fleets in the BAM models (indicated by “.D”).
The black seabass stock has two commercial fleets (cHL and cPT), but the discards are reported for two fleets combined (cGN.D). To deal with this, the cHL and cPT landing fleets will first be combined together, before the discards are added for the combined fleet.
Here we create a data frame with Code, Name, Mapping, and Type for each fleet:
fleet_df <- data.frame(Code=unique(fleet_names_df$Fleets))
fleet_df$Name <- c('Commercial Line',
'Recreational Headboat',
'General Recreational',
'Commercial Line - Discard',
'Recreational Headboat - Discard',
'General Recreational - Discard',
'Commercial Dive',
'Commercial Pot',
'Commercial General - Discard')
fleet_df$Mapping <- c(1,2,3,1,2,3,4,1,1)
fleet_df$Type <- 'Landing'
fleet_df$Type[grepl('\\.D', fleet_df$Code)] <- 'Discard'
fleet_df
#> Code Name Mapping Type
#> 1 cHL Commercial Line 1 Landing
#> 2 rHB Recreational Headboat 2 Landing
#> 3 rGN General Recreational 3 Landing
#> 4 cHL.D Commercial Line - Discard 1 Discard
#> 5 rHB.D Recreational Headboat - Discard 2 Discard
#> 6 rGN.D General Recreational - Discard 3 Discard
#> 7 cDV Commercial Dive 4 Landing
#> 8 cPT Commercial Pot 1 Landing
#> 9 cGN.D Commercial General - Discard 1 DiscardCode is the name of the fleets within the OM objects. Name is the name we are associating with each Code. The Mapping variable describes how the fleets will be combined together. Type indicates if a fleet in the OM represents Landings or Discards.
The Landing and Discard components for each fleet will be combined into a single fleet with a selectivity and retention curve. This makes it easier to model changes to management such as changes to season lengths, discard mortality, or size-based retention or selectivity regulations.
The end result will be a fleet structure with four fleets for each stock:
- Commercial Line
- Recreational Headboat
- General Recreational
- Commercial Dive
5.2 Define Discard Mortality
The discard mortality needs to be added to the OMs so that the historical effort can be adjusted to account for the fish that were caught and released alive, and so that the discard mortality can be modified in the projections.
The discard mortality for red dnapper is reported in Table 6 of SEDAR 73. TheYear variable indicates the first year the discard mortality changes:
discard_mortality_RS <- dplyr::bind_rows(
data.frame(Stock='Red Snapper',
Code='cHL',
Year=c(1900, 2007, 2017),
Prob_Dead=c(0.48, 0.38, 0.36)),
data.frame(Stock='Red Snapper',
Code='rHB',
Year=c(1900, 2011, 2018),
Prob_Dead=c(0.37, 0.26, 0.25)),
data.frame(Stock='Red Snapper',
Code='rGN',
Year=c(1900, 2011, 2018),
Prob_Dead=c(0.37, 0.28, 0.26))
)The discard mortality for Gag Grouper is reported in SEDAR 71, with a fixed discard mortality of 0.4 for the commerical fleet, and 0.25 for the recreational fleets for all years:
discard_mortality_GG <- dplyr::bind_rows(
data.frame(Stock='Gag Grouper',
Code='cHL',
Year=1900,
Prob_Dead=0.4),
data.frame(Stock='Gag Grouper',
Code='rHB',
Year=1900,
Prob_Dead=0.25),
data.frame(Stock='Gag Grouper',
Code='rGN',
Year=1900,
Prob_Dead=0.25)
)The discard mortality for Black Seabass is reported in Section 2.2.1 in SEDAR 76. Here the average discard mortality is calculated for the combined commercial line and pot fleets:
discard_mortality_BS <- dplyr::bind_rows(
data.frame(Stock='Black Sea Bass',
Code='cHL',
Year=c(1900, 2007),
Prob_Dead=c(mean(c(0.14,0.19)), mean(c(0.14, 0.068)))
),
data.frame(Stock='Black Sea Bass',
Code='rHB',
Year=1900,
Prob_Dead=0.152),
data.frame(Stock='Black Sea Bass',
Code='rGN',
Year=1900,
Prob_Dead=0.137)
)The stock-specific discard mortality dataframes are combined together:
discard_mortality <- dplyr::bind_rows(discard_mortality_RS,
discard_mortality_GG,
discard_mortality_BS)5.3 Aggregate Fleets
Next, the Aggregate_Fleets function is used to aggregate the fleets together according to the mapping defined in fleet_df and the discard mortality are added from discard_mortality.
The Aggregate_Fleets function does five things:
- Combine any landing fleets that are mapped together in
fleet_df(here only applies to Black Seabass) - Add the discard mortality to each fleet
- Combine the discard fleets with the landing fleets to produce a single fleet with selectivity and retention curves
- Add dummy fleets (F=0 for all years) for OMs that are missing some fleets
- Order the fleets for all OMs
OM_RSTEMP <- Aggregate_Fleets(OM_RS, fleet_df, discard_mortality)
OM_RSTEMP@cpars$`Red Snapper`$`Commercial Line`$Find[1,]
OM_RSTEMP@cpars$`Red Snapper`$`Commercial Line`$V[1,,1]
OM_RSTEMP@cpars$`Red Snapper`$`Commercial Line`$V[1,,43]
OM_RSTEMP@cpars$`Red Snapper`$`Commercial Line`$retA[1,,43]
OM_RSTEMP@cpars$`Red Snapper`$`Commercial Line`$V[1,,70]
OM_RSTEMP@cpars$`Red Snapper`$`Commercial Line`$retA[1,,70]
OM_RS <- Aggregate_Fleets(OM_RS, fleet_df, discard_mortality)
OM_GG <- Aggregate_Fleets(OM_GG, fleet_df, discard_mortality)
OM_BS <- Aggregate_Fleets(OM_BS, fleet_df, discard_mortality)6 Add Spatial Structure
The spatial structure of the MSE has been defined as 6 areas, including 3 geographic regions and a Nearshore (<100ft) and Offshore (>100ft) component for each region (solid and dashed black lines respectively in Figure 6.1).
require(marmap)
bathy <- marmap::getNOAA.bathy(-83, -71.37133, 23.8, 36.55028)
numbers <- data.frame(Number=1:6,
x=c(-79.5, -77.7, -81, -80.3, -82, -80.3),
y=c(33, 33, 30, 30, 25, 25))
map <- ggplot()+
geom_raster(data=bathy, aes(x=x, y=y,fill=z)) +
coord_sf() +
marmap::scale_fill_etopo() +
guides(fill='none') +
ggnewscale::new_scale_fill() +
geom_polygon(data = Spatial_Area_Definition(),
aes(x = X, y = Y, group=Region, fill=Region), alpha=0.5) +
scale_fill_manual(values= c('#7fc97f', '#beaed4', '#fdc086')) +
geom_contour(data=bathy, aes(x=x, y=y, z=z), breaks=c(-30),
colour="black",linewidth=0.2) +
geom_contour(data=bathy, aes(x=x, y=y, z=z), breaks=c(-300),
colour="black",linewidth=0.2, linetype=2) +
geom_text(data=numbers, aes(x=x, y=y, label=Number), size=5) +
scale_x_continuous(expand=c(0,0)) +
scale_y_continuous(expand=c(0,0)) +
labs(x='Longitude', y='Latitude') +
theme(plot.margin=grid::unit(c(0,0,0,0), "mm"))
map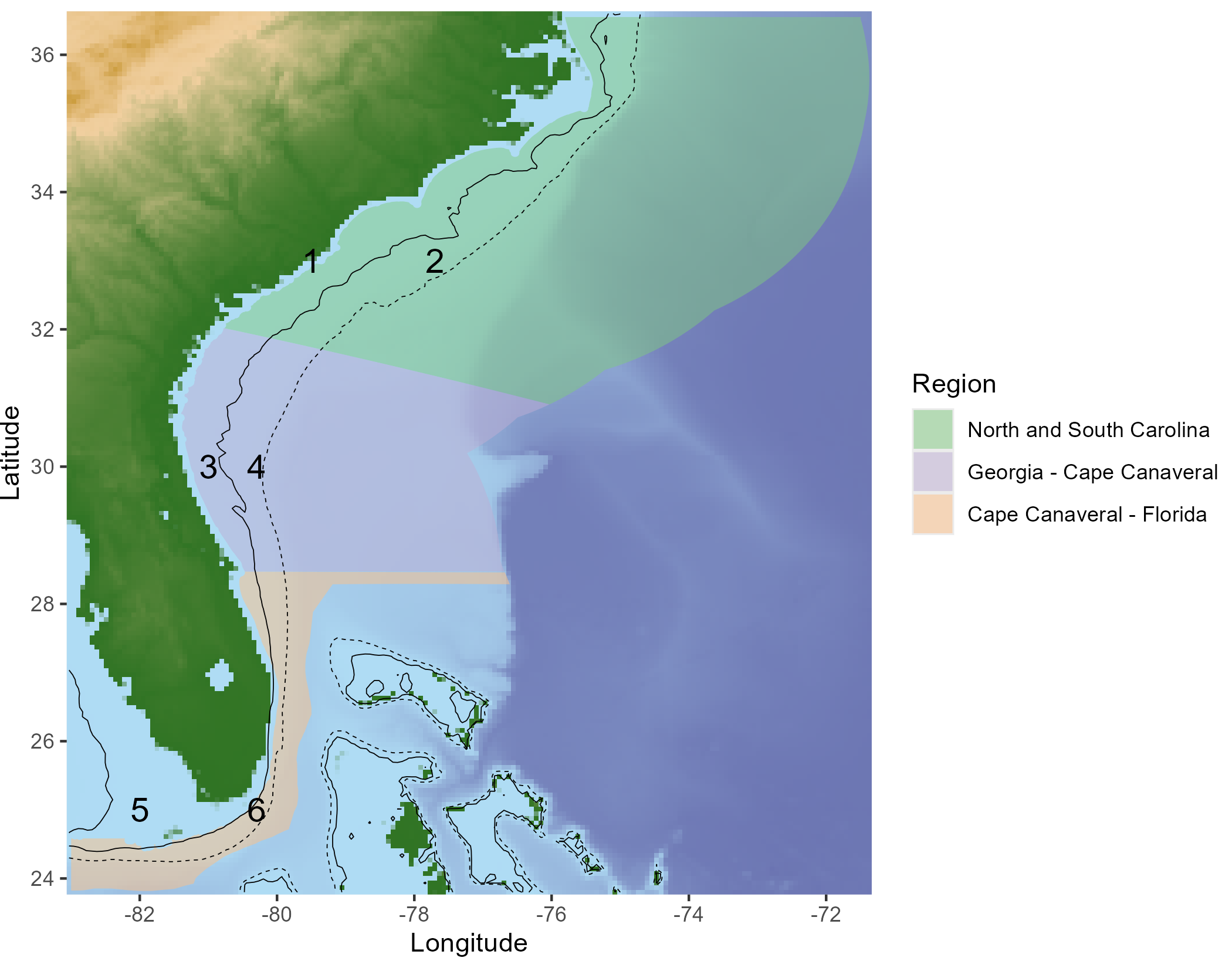
Figure 6.1: Definition of the spatial areas used in the MSE.
6.1 Spatial Distribution of Unfished Abundance
The relative abundance of the three stocks was specified using the output of a recent study that estimated the spatiotemporal dynamics of reef fish off the southeastern United States (Cao et al., 2024; K. Shertzer personal communication, May 2024).
Rel_Abun_Area_RS <- data.frame(
Area=1:6,
Region=c(rep('North and South Carolina',2),
rep('Georgia - Cape Canaveral',2),
rep('Cape Canaveral - Florida',2)),
Depth=c('Nearshore', 'Offshore'),
Stock='Red Snapper',
Proportion=c(0.095, 0.048, 0.497, 0.309, 0.020, 0.031)
)
Rel_Abun_Area_GG <- data.frame(
Area=1:6,
Region=c(rep('North and South Carolina',2),
rep('Georgia - Cape Canaveral',2),
rep('Cape Canaveral - Florida',2)),
Depth=c('Nearshore', 'Offshore'),
Stock='Gag Grouper',
Proportion=c(0.318, 0.298, 0.148, 0.182, 0.025, 0.029)
)
Rel_Abun_Area_BS <- data.frame(
Area=1:6,
Region=c(rep('North and South Carolina',2),
rep('Georgia - Cape Canaveral',2),
rep('Cape Canaveral - Florida',2)),
Depth=c('Nearshore', 'Offshore'),
Stock='Black Seabass',
Proportion=c(0.449, 0.055, 0.415, 0.047, 0.027, 0.008)
)6.2 Add Stock Spatial Structure to OMs
The age-specific relative distribution of each stock across the depth zones was modeled by assuming 100%, 95%, and 80% of age-0, -1, and -2 fish respectively occurred in the nearshore region.
The depth distribution of age-3+ fish, as well as the relative spatial distribution of the fishing fleets, were then calculated by optimizing the age-3+ stock and the fleet-specific effort spatial distributions such that the relative distribution of the biomass across the six areas in the terminal year of the operating models closely matched the reported relative distribution from the spatiotemporal model (see above).
OM_RS <- Add_Spatial_to_OM(OM_RS, Rel_Abun_Area_RS)
OM_GG <- Add_Spatial_to_OM(OM_GG, Rel_Abun_Area_GG)
OM_BS <- Add_Spatial_to_OM(OM_BS, Rel_Abun_Area_BS)7 Generate Correlated Recruitment Deviations for Projections
A multivariate normal distribution (truncated at 2 standard deviations) was used to estimate the variance and auto-correlation in the estimated recruitment deviations, together with the correlation in recruitment deviations between the three stocks. This distribution was then used to generate recruitment deviations for the projection period, maintaining the statistic properties of the historical recruitment deviations estimated in the stock assessments (Figure 7.1).
OMList <- Generate_Correlated_Rec_Devs(list(OM_RS, OM_GG, OM_BS), truncsd=2)
Plot_Correlated_Rec_Devs(OMList)
OM_RS <- OMList[[1]]
OM_GG <- OMList[[2]]
OM_BS <- OMList[[3]]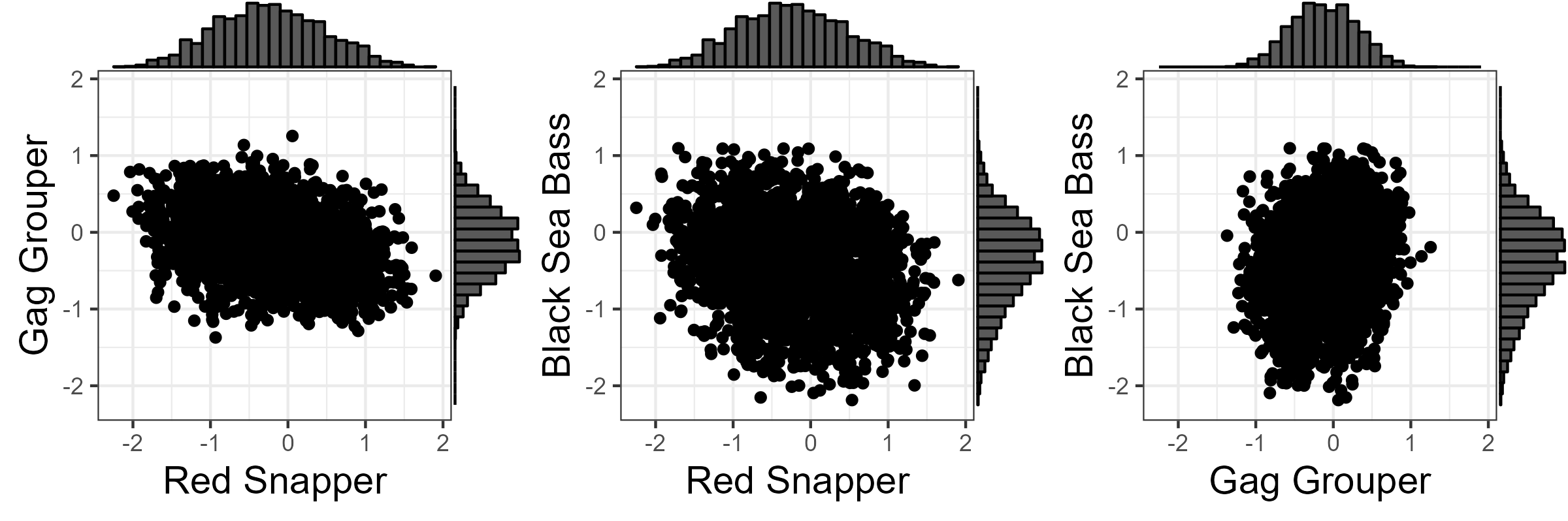
Figure 7.1: Scatterplots with marginal distributions showing the correlated recruitment deviations used for the projections.
8 Compare BAM and OM Dynamics
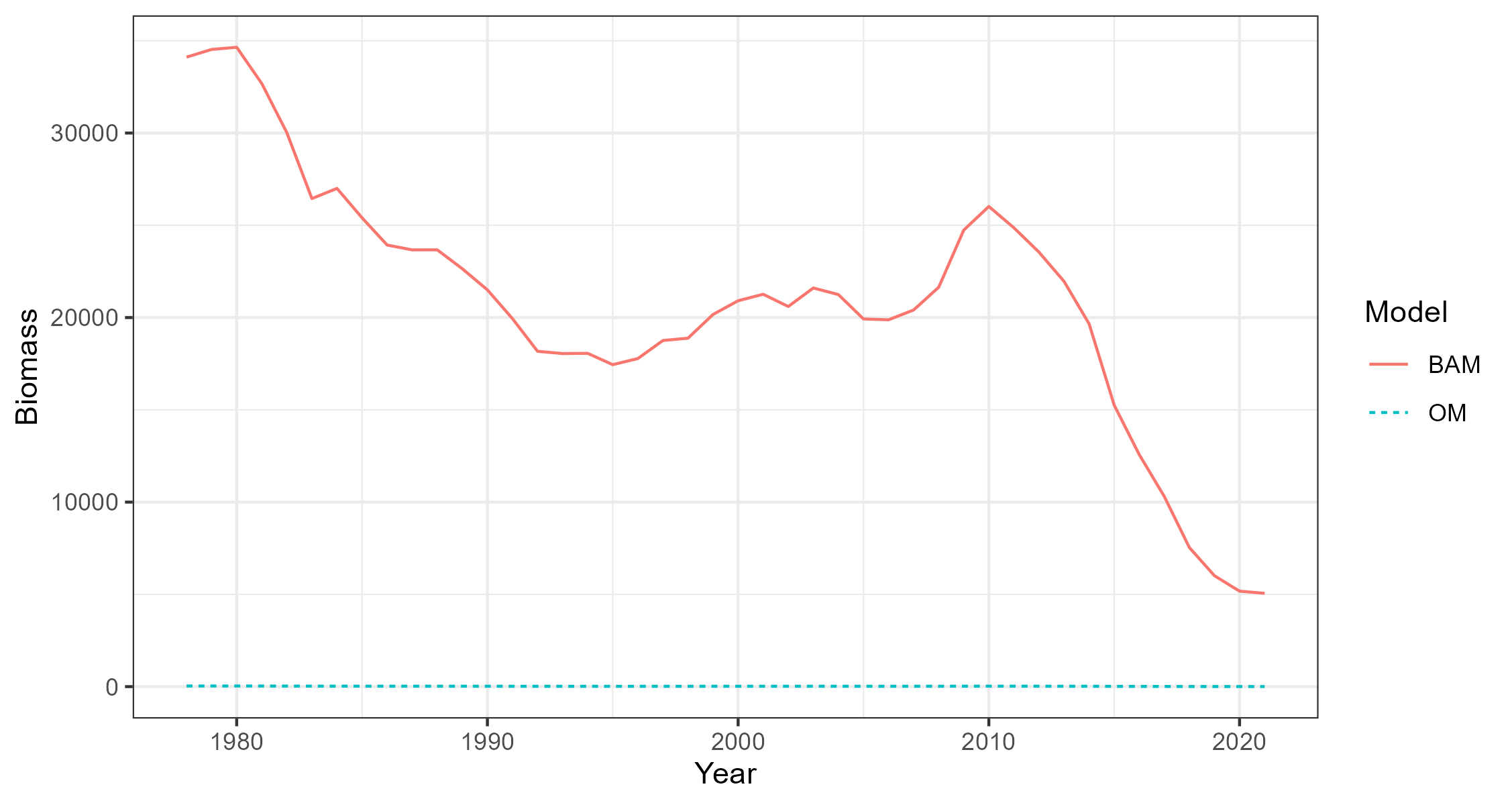
Three single-stock, multi-fleet operating models have now been created. The next thing is to confirm that the fishery dynamics generated by the operating model are sufficiently close to those estimated in the BAM output.
Here the Simulate function is used to simulate the historical fishery dynamics described in the OM, and the
Compare_Biomass function creates a plot to compare the biomass from the OM with those from the BAM output.
The plots show that the biomass generated by the OMs closely matches the biomass reported by the stock assessments. The minor differences between the two are caused by the spatial structure being imposed onto the output of a non-spatial stock assessment.
Hist_RS <- Simulate(OM_RS, silent = TRUE, nsim=2)
Compare_Biomass(Hist_RS, rdat_RS)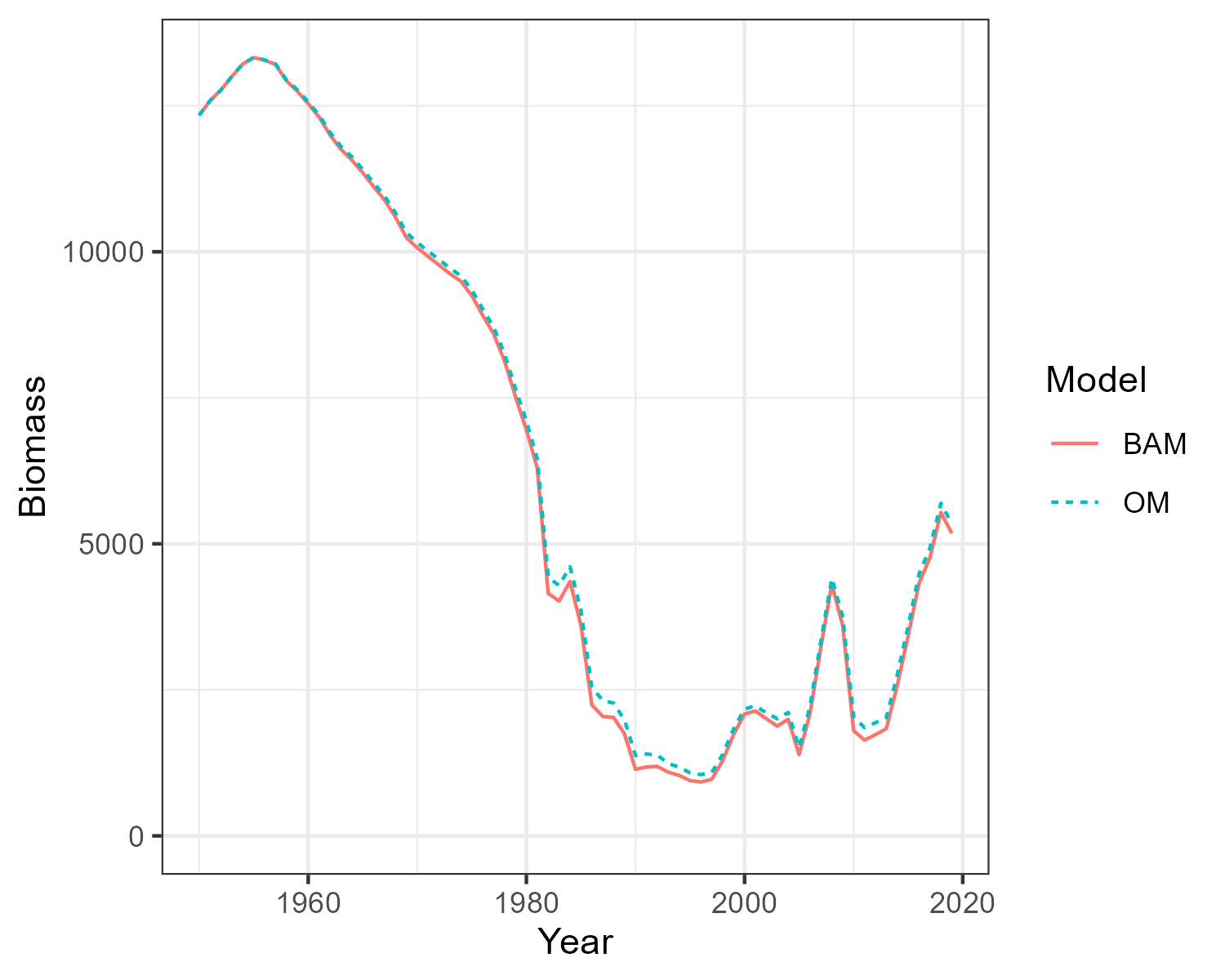
Hist_GG <- Simulate(OM_GG, silent = TRUE, nsim=2)
Compare_Biomass(Hist_GG, rdat_GG)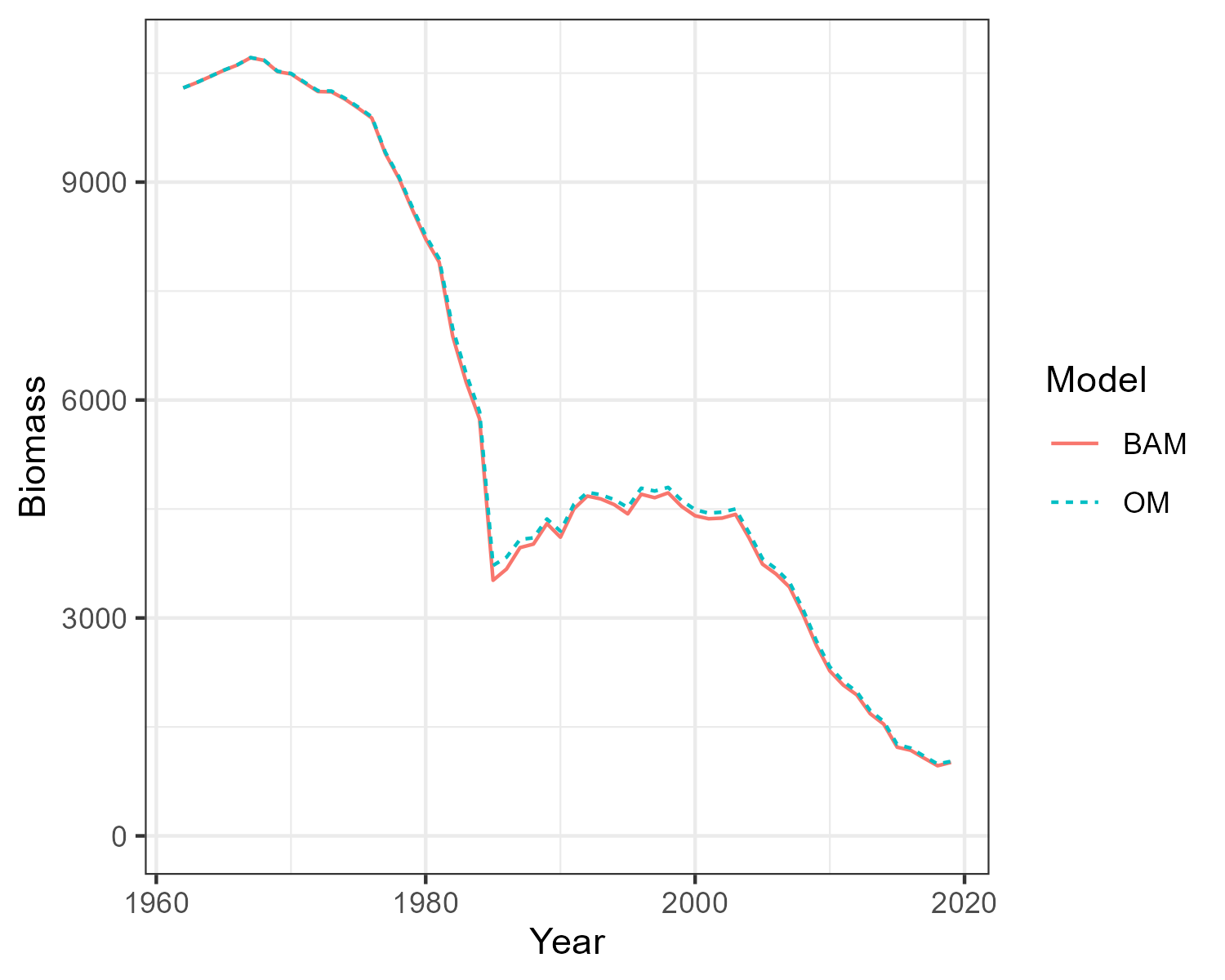
Hist_BS <- Simulate(OM_BS, silent = TRUE, nsim=2)
Compare_Biomass(Hist_BS, rdat_BS)